


생성형 AI 마스터하기 5편: 대규모 언어 모델(LLM) 완전 정복! AI는 어떻게 말을 할까?
지난 4편에서는 새롭고 독창적인 콘텐츠를 만들어내는 생성형 AI의 놀라운 세계를 살펴보았습니다. 그림을 그리고, 음악을 작곡하며, 심지어 코드를 짜는 AI까지! 이제 우리는 이러한 생성형 AI, 특히 텍스트를 다루는 AI들이 어떻게 그렇게 인간처럼 자연스럽게 말하고 글을 쓸 수 있는지, 그 핵심 두뇌인 대규모 언어 모델(Large Language Models, LLM)에 대해 깊이 알아볼 시간입니다.

대규모 언어 모델(LLM)이란 무엇일까요?
대규모 언어 모델(LLM)은 이름에서 알 수 있듯이, 엄청나게 큰 규모의 텍스트 데이터로 훈련된 딥러닝 모델입니다. 수십억 개에서 수조 개에 이르는 매개변수(파라미터)를 가지고 있으며, 인터넷의 거의 모든 텍스트(책, 기사, 웹사이트, 대화 등)를 학습했다고 해도 과언이 아닙니다. 이렇게 방대한 데이터를 통해 LLM은 인간 언어의 복잡한 패턴, 문법, 문맥, 심지어 세상의 지식까지 학습하게 됩니다.
LLM은 단순히 특정 작업만 잘하는 AI가 아니라, 매우 광범위한 언어 관련 작업을 수행할 수 있는 '일반적인' 언어 능력을 갖추고 있다는 점에서 이전의 언어 모델들과 차별화됩니다.
LLM의 핵심 특징들
-
엄청난 모델 크기 및 데이터: 수많은 매개변수와 방대한 텍스트 데이터로 학습하여 뛰어난 언어 이해 및 생성 능력을 갖습니다.
-
뛰어난 문맥 이해: 단어의 의미뿐만 아니라 문맥 속에서 어떻게 사용되는지, 대화의 흐름이 어떻게 이어지는지를 깊이 이해합니다.
-
다재다능한 작업 수행: 번역, 요약, 작문, 질의응답, 코드 생성 등 다양한 언어 관련 작업을 별도의 추가 학습 없이도 어느 정도 수행할 수 있습니다. (Zero-shot, Few-shot learning)
-
일관성 있는 텍스트 생성: 문법적으로 정확하고, 논리적으로 일관되며, 주어진 문맥에 맞는 자연스러운 텍스트를 생성합니다.
LLM은 어떻게 작동할까요? (핵심 기술 엿보기)
LLM의 놀라운 능력 뒤에는 정교한 기술들이 숨어있습니다. 그 핵심적인 작동 방식을 간략히 살펴볼까요?
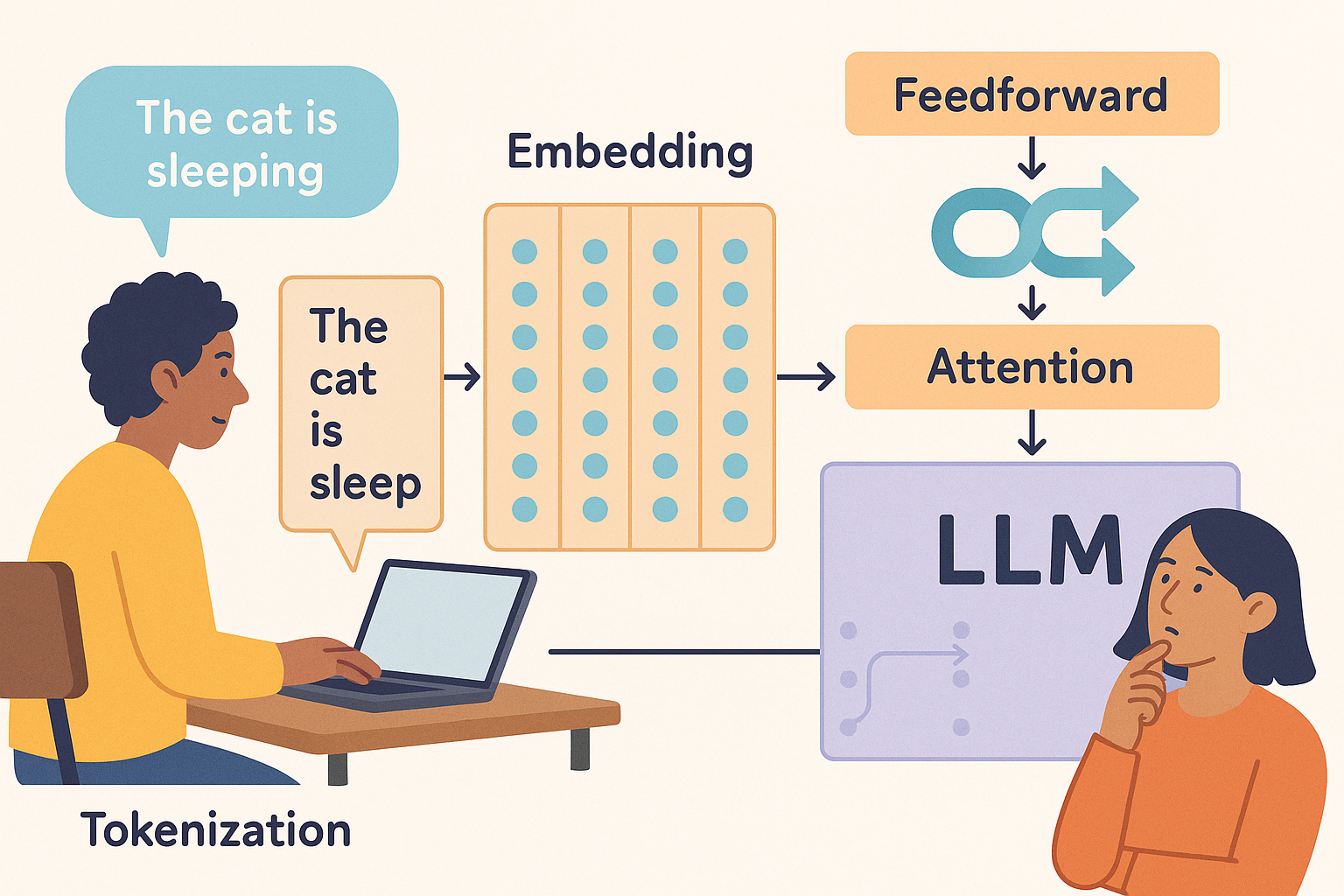
1. 트랜스포머 아키텍처 (Transformer Architecture)
대부분의 현대 LLM은 트랜스포머라는 딥러닝 아키텍처를 기반으로 합니다. (3편에서 자세히 다뤘죠!) 트랜스포머의 핵심은 '셀프 어텐션(Self-Attention)' 메커니즘으로, 문장 내 각 단어가 다른 단어들과 얼마나 연관되어 있는지, 어떤 단어에 더 주목해야 하는지를 파악하여 문맥을 효과적으로 이해합니다. 이를 통해 긴 문장이나 복잡한 문맥도 잘 처리할 수 있습니다.
2. 토큰화 (Tokenization)
LLM이 텍스트를 처리하기 위해서는 먼저 텍스트를 작은 단위로 나누어야 합니다. 이 과정을 토큰화라고 하며, 나누어진 단위를 토큰(Token)이라고 합니다. 토큰은 단어일 수도 있고, 더 작은 하위 단어(subword)나 문자일 수도 있습니다. 예를 들어 "나는 오늘 행복하다"라는 문장은 ["나", "는", "오늘", "행복", "하다"] 와 같이 토큰화될 수 있습니다.
3. 임베딩 (Embeddings)
토큰화된 각 토큰은 컴퓨터가 이해할 수 있는 숫자 형태, 즉 벡터(Vector)로 변환됩니다. 이 과정을 임베딩이라고 하며, 생성된 벡터를 임베딩 벡터라고 합니다. 임베딩 벡터는 단어의 의미를 수치적으로 표현하며, 의미가 비슷한 단어들은 벡터 공간에서 서로 가까이 위치하게 됩니다. (예: '사과'와 '오렌지'는 '자동차'보다 서로 가까이 위치)
4. 사전 훈련 (Pre-training) 및 미세 조정 (Fine-tuning)
사전 훈련은 LLM이 방대한 양의 일반 텍스트 데이터를 통해 기본적인 언어 이해 능력과 세상의 지식을 학습하는 과정입니다. 이 과정에서 모델은 다음 단어를 예측하거나 문장 중간의 빈칸을 채우는 등의 작업을 수행하며 스스로 학습합니다.
미세 조정은 사전 훈련된 LLM을 특정 작업이나 도메인에 더 잘 맞도록 추가적으로 학습시키는 과정입니다. 예를 들어, 일반적인 LLM을 의료 분야 텍스트 데이터로 미세 조정하면 의료 관련 질문에 더 전문적인 답변을 할 수 있게 됩니다.
이러한 과정을 통해 LLM은 인간의 언어를 깊이 이해하고, 다양한 상황에 맞는 적절한 텍스트를 생성할 수 있는 능력을 갖추게 됩니다.
LLM의 종류와 대표 주자들
현재 수많은 종류의 LLM이 개발되어 활용되고 있습니다. 몇 가지 유명한 모델들을 살펴볼까요?
GPT 시리즈 (OpenAI)
Generative Pre-trained Transformer의 약자로, OpenAI가 개발한 대표적인 LLM입니다. ChatGPT의 기반이 되는 모델로, 자연스러운 대화, 글쓰기, 코딩 등 다양한 작업에서 뛰어난 성능을 보여줍니다. (GPT-3, GPT-3.5, GPT-4 등)
BERT (Google)
Bidirectional Encoder Representations from Transformers의 약자로, 구글이 개발한 모델입니다. 문맥을 양방향으로 이해하는 능력이 뛰어나 검색 엔진, 질의응답 시스템 등에서 널리 활용됩니다.
LaMDA & PaLM (Google)
LaMDA는 대화형 애플리케이션에 특화된 모델이며, PaLM은 더욱 방대한 매개변수를 가진 차세대 LLM으로 다양한 언어 작업에서 높은 성능을 목표로 합니다. 구글의 Bard(현 Gemini) 등에 활용되었습니다.
기타 LLM들
Meta의 LLaMA, 스탠포드 대학의 Alpaca, 국내 기업(네이버, 카카오, LG 등)이 개발한 LLM 등 전 세계적으로 다양한 LLM들이 연구되고 발전하고 있습니다.
LLM, 어디에 어떻게 사용될까요? (응용 분야)
LLM의 강력한 언어 능력은 이미 다양한 분야에서 혁신적인 변화를 만들어내고 있습니다.
-
챗봇 및 가상 비서: 고객 서비스, 정보 제공, 개인 맞춤형 대화. (예: ChatGPT, Gemini)
-
기계 번역: 다양한 언어 간의 실시간 고품질 번역.
-
콘텐츠 생성 및 작문 보조: 기사, 블로그, 소설, 시나리오, 마케팅 문구 작성 지원.
-
정보 검색 및 요약: 방대한 문서에서 핵심 정보 추출 및 요약.
-
코드 생성 및 개발 지원: 자연어 설명을 바탕으로 프로그래밍 코드 생성 또는 디버깅 지원.
-
교육 및 학습: 개인 맞춤형 학습 자료 제공, 질의응답을 통한 학습 지원.
LLM의 그림자: 한계와 과제
LLM은 놀라운 능력을 보여주지만, 아직 완벽하지는 않습니다. 몇 가지 중요한 한계와 해결해야 할 과제들이 있습니다.
- 환각 현상 (Hallucination): 때때로 사실이 아니거나 맥락에 맞지 않는 정보를 그럴듯하게 생성하는 경우가 있습니다.
- 편향성 (Bias): 학습 데이터에 포함된 사회적 편견이나 차별적인 내용을 그대로 학습하여 결과물에 반영할 수 있습니다.
- 최신 정보 부족: 특정 시점까지의 데이터로 학습하기 때문에, 그 이후의 최신 정보나 사건에 대해서는 알지 못할 수 있습니다.
- 높은 계산 비용: LLM을 학습하고 운영하는 데에는 막대한 양의 컴퓨팅 자원과 에너지가 소모됩니다.
- 윤리적 문제: 악의적인 목적으로 사용될 경우 가짜 뉴스 확산, 지적 재산권 침해 등의 문제가 발생할 수 있습니다.
이러한 문제 해결을 위한 연구와 노력이 지속적으로 이루어지고 있습니다.
다음 이야기: LLM과 대화하는 기술, 프롬프트 엔지니어링!
대규모 언어 모델(LLM)이 어떻게 작동하고, 어떤 능력을 가졌는지 이제 잘 아시겠죠? LLM은 마치 엄청난 지식을 가진 똑똑한 대화 상대와 같습니다. 하지만 이 똑똑한 AI에게서 우리가 원하는 답변이나 결과물을 얻어내려면, 효과적으로 질문하고 지시하는 방법, 즉 '대화의 기술'이 필요합니다.
다음 편에서는 LLM과 효과적으로 소통하는 기술인 '프롬프트 엔지니어링(Prompt Engineering)'에 대해 자세히 알아봅니다. 좋은 프롬프트란 무엇이고, 어떻게 작성해야 LLM의 잠재력을 최대한 끌어낼 수 있을까요? AI에게 원하는 것을 정확히 얻어내는 마법 같은 대화법을 배우고 싶다면 다음 편을 기대해주세요!
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
'취미 > AI' 카테고리의 다른 글
| 생성형 AI 마스터하기 7편: AI 시대의 나침반, 생성형 AI의 윤리적 고려사항 (27) | 2025.05.22 |
|---|---|
| 생성형 AI 마스터하기 6편: AI와 대화하는 기술, 프롬프트 엔지니어링이란? (39) | 2025.05.21 |
| 생성형 AI 마스터하기 4편: 창조하는 AI의 등장! 생성형 AI란 무엇인가? (59) | 2025.05.20 |
| 생성형 AI 마스터하기 3편: 딥러닝 파헤치기! 인간의 뇌를 닮은 AI (51) | 2025.05.20 |
| 생성형 AI 마스터하기 2편: 머신러닝 완전 정복! AI를 똑똑하게 만드는 비밀 (65) | 2025.05.19 |